Zixuan Huang
zxhuang1698@gmail.com
![]()
![]()
![]()
![]()
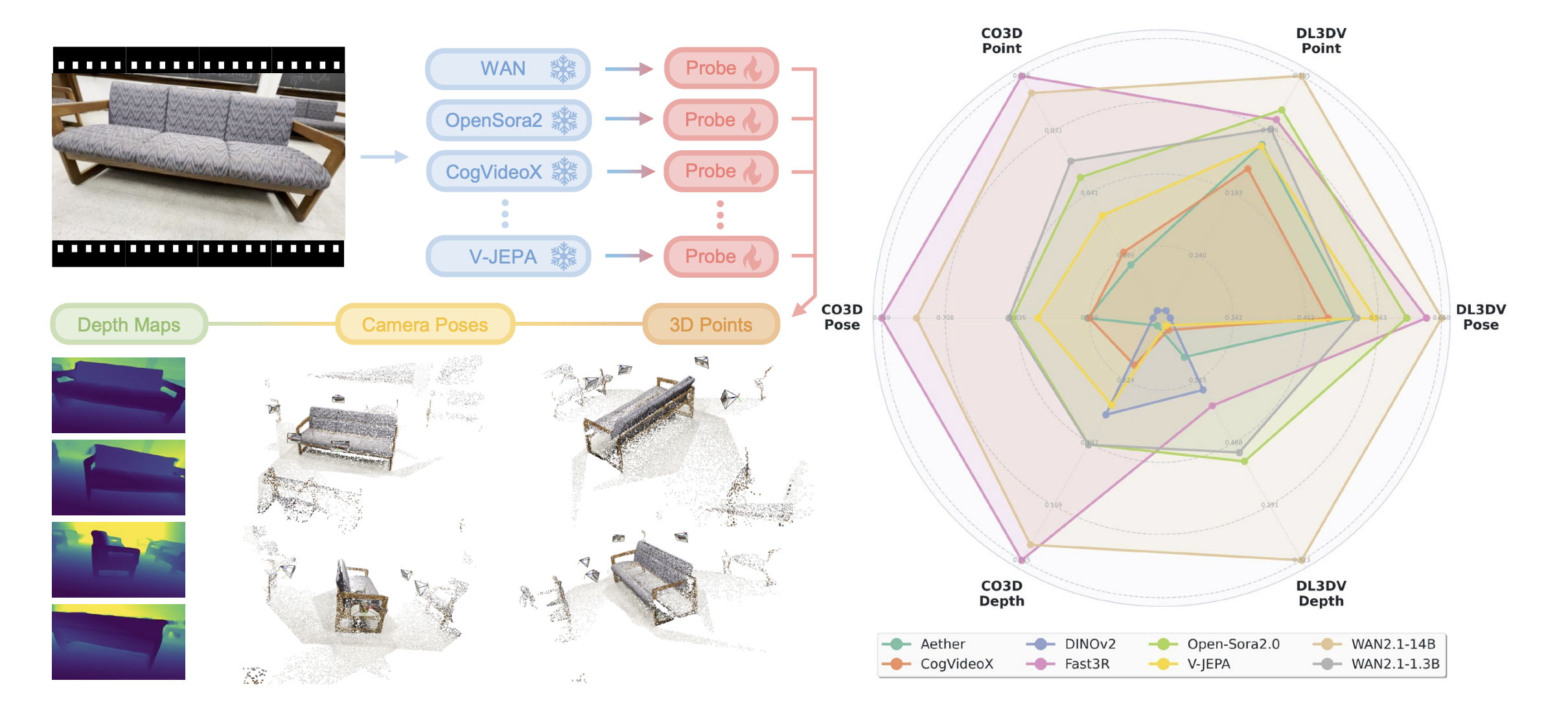
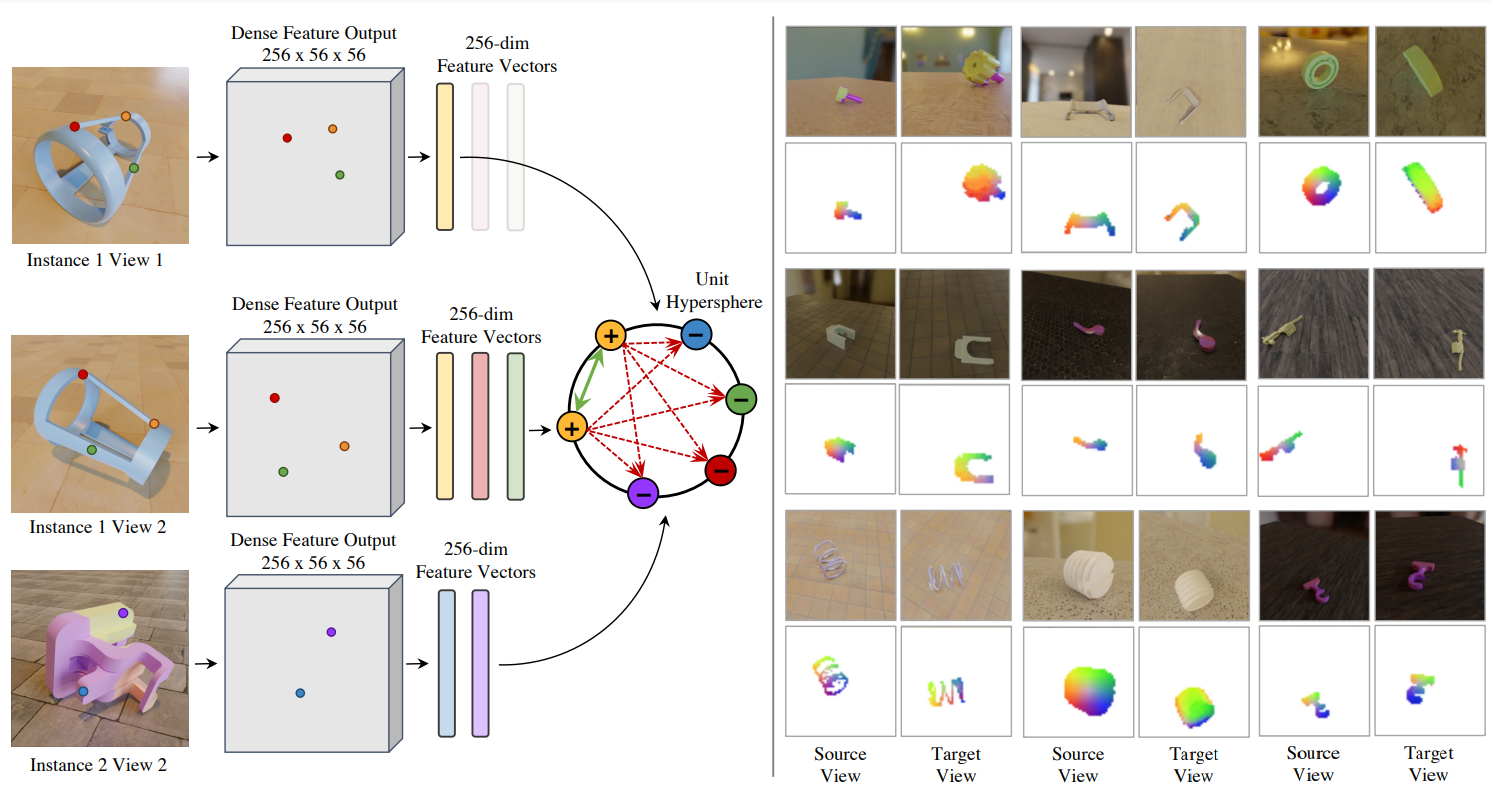
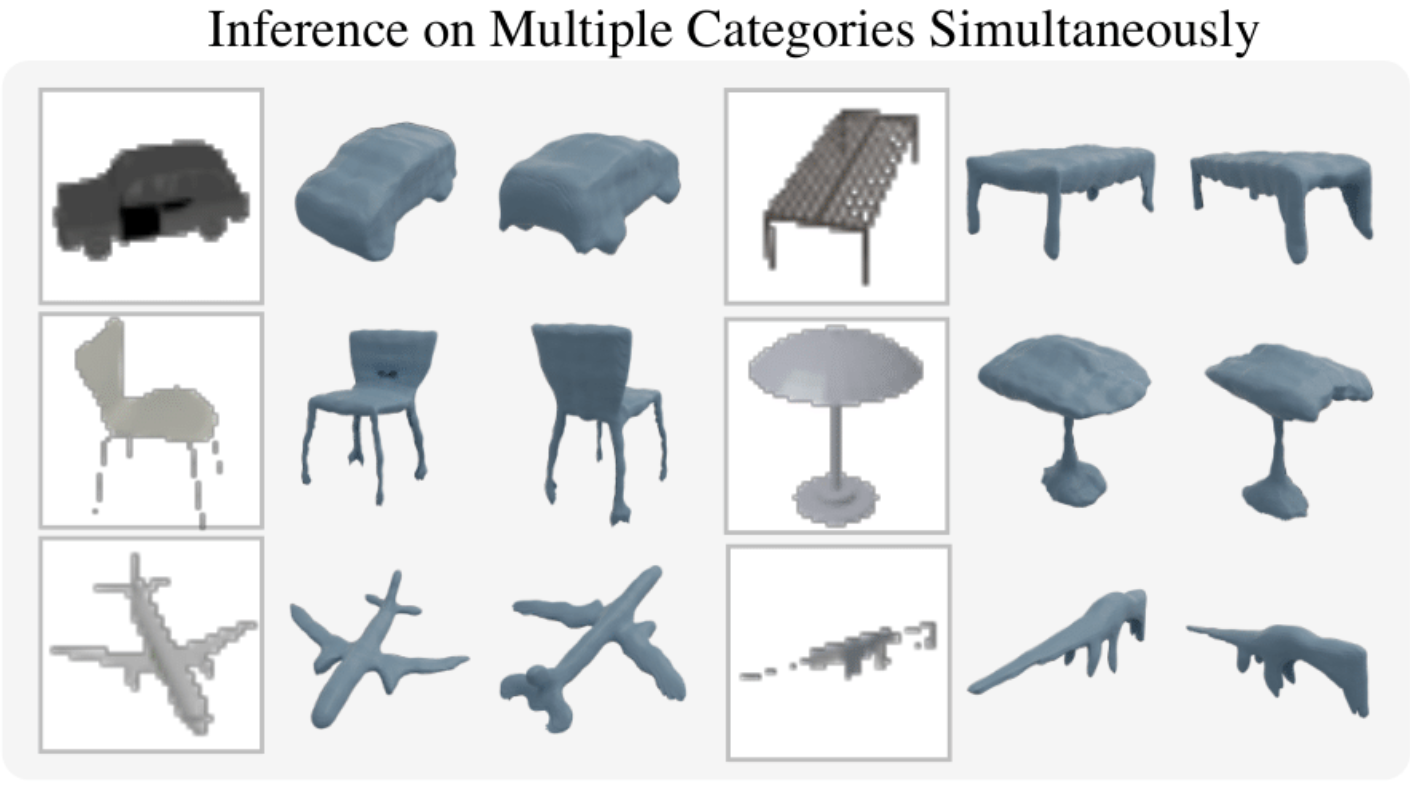
My name is Zixuan Huang (黄子煊, pronounced as Zi-Shwan Hwung), currently a Member of Technical Staff at World Labs. Previously, I was a Research Scientist at Meta Reality Labs. I received my PhD at University of Illinois Urbana-Champaign, advised by James Rehg. I got my masters degree at University of Wisconsin-Madison, where I worked with Professor Yin Li. I received my B.E. in the Special Class for Gifted Young from University of Science and Technology of China in 2018. My research centers on scalable 3D generation, with the goal of automatically creating immersive 3D worlds.
In the past, I have also interned with Varun Jampani and Mark Boss at Stability AI, Chao-Yuan Wu and Justin Johnson at FAIR Labs (Meta AI), Varun Jampani and Yuanzhen Li at Google Research, as well as Hongsheng Li and Shuai Yi at Sensetime.