Abstract
We present PointInfinity, an efficient family of point cloud diffusion models. Our core idea is to use a transformer-based architecture with a fixed-size, resolution-invariant latent representation. This enables efficient training with low-resolution point clouds, while allowing high-resolution point clouds to be generated during inference. More importantly, we show that scaling the test-time resolution beyond the training resolution improves the fidelity of generated point clouds and surfaces. We analyze this phenomenon and draw a link to classifier-free guidance commonly used in diffusion models, demonstrating that both allow trading off fidelity and variability during inference. Experiments on CO3D show that PointInfinity can efficiently generate high-resolution point clouds (up to 131k points, 31 times more than Point-E) with state-of-the-art quality.
How Does PointInfinity Work?
PointInfinity is a conditional point diffusion model that generates point clouds based on RGBD images. During training, PointInfinity learns to denoise low-resolution point clouds, while during inference it generates point clouds of much higher resolution. The figure below is an overview of PointInfinity's setup.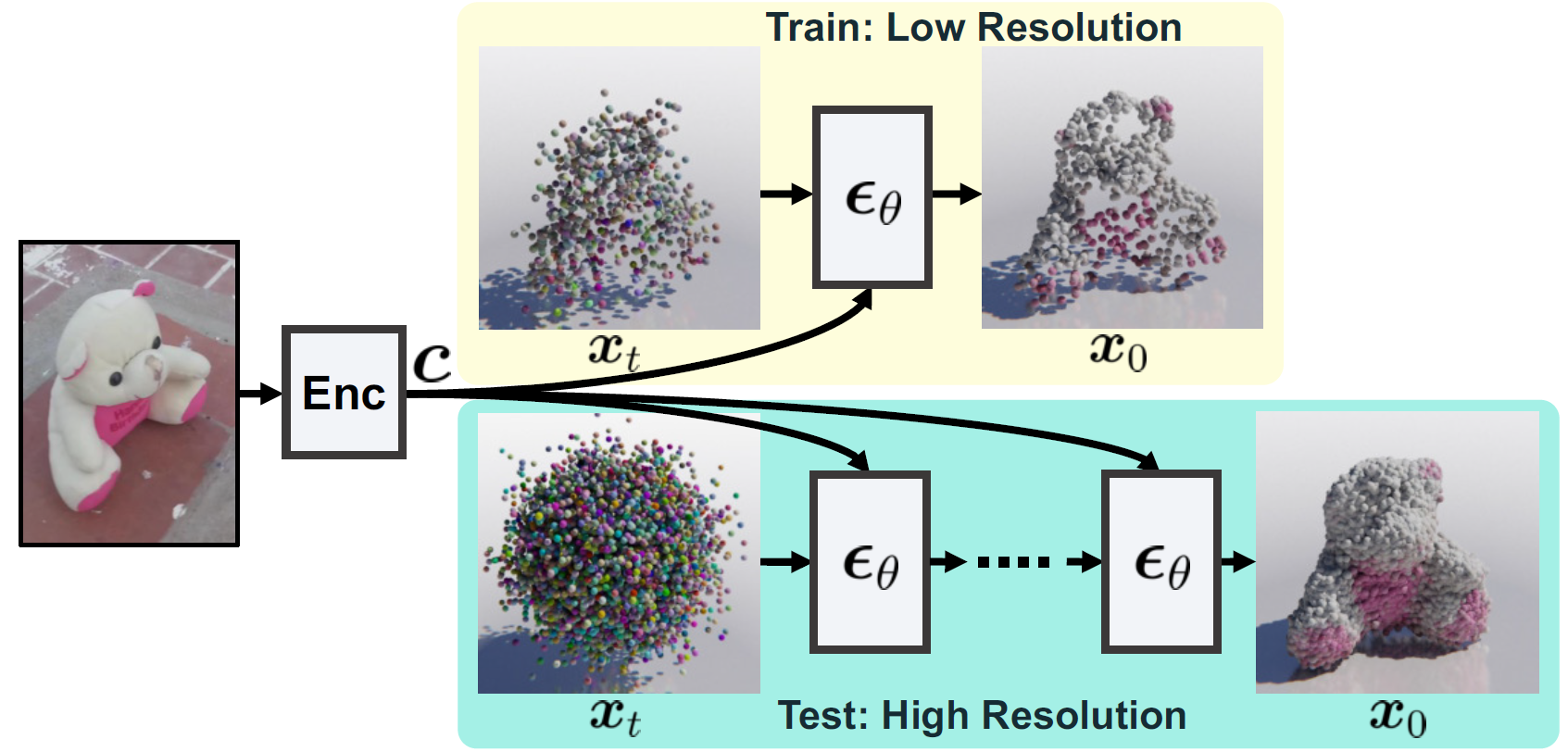
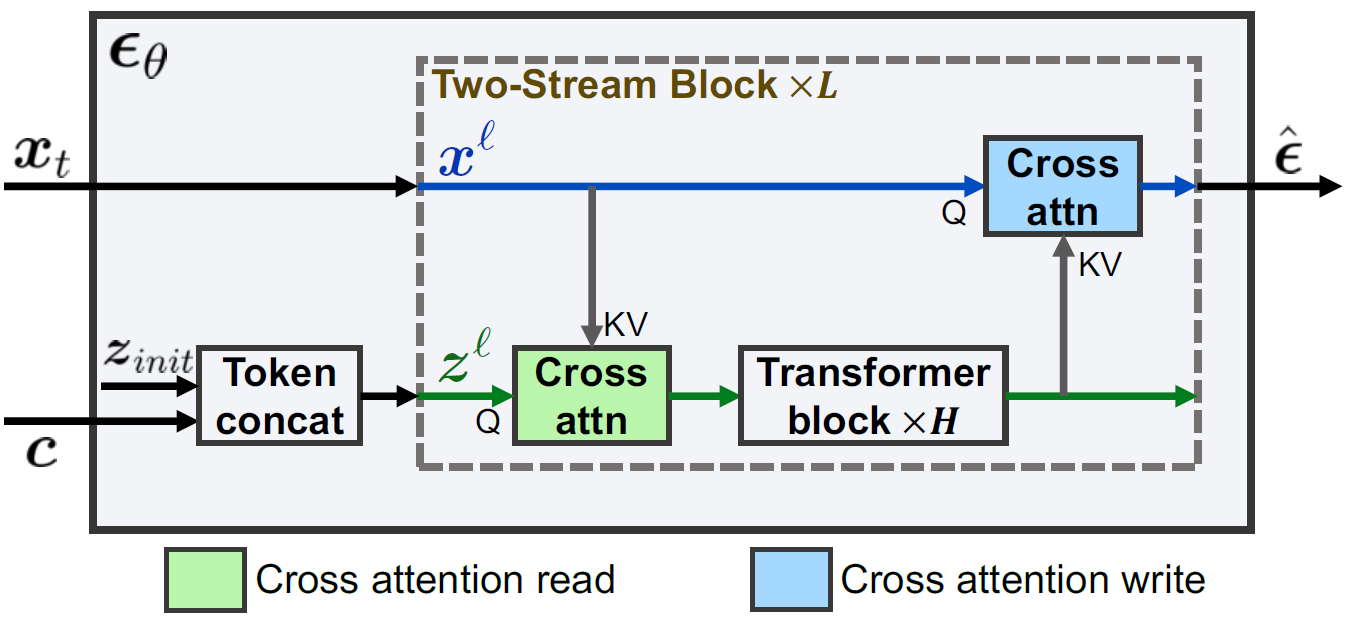
Results
We evaluate PointInfinity on the CO3D dataset. The figure below shows the qualitative results of PointInfinity. When generating higher resolution point clouds, PointInfinity's performance improves. We hypothesize that this is related to more information being carried across the diffusion steps. Please refer to our paper for a thorough analysis, together with more quantitative results and ablations.
BibTeX
@inproceedings{huang2024pointinfinity,
author = {Huang, Zixuan and Johnson, Justin and Debnath, Shoubhik and Rehg, James M and Wu, Chao-Yuan},
title = {PointInfinity: Resolution-Invariant Point Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages = {10050--10060},
year = {2024},
}